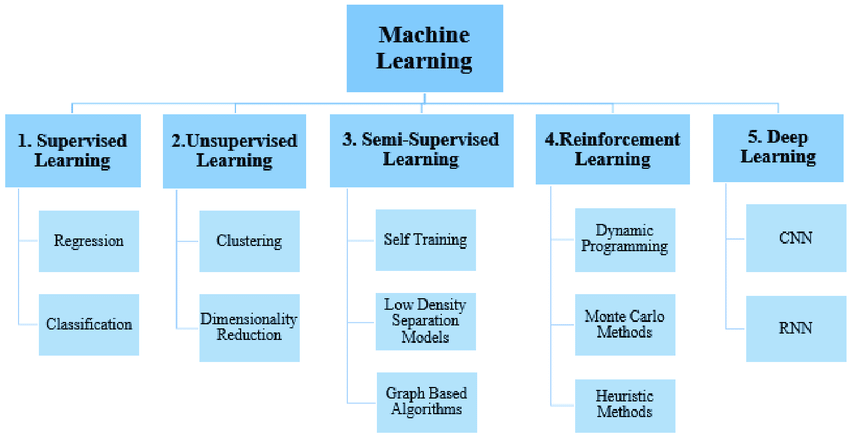
Machine learning is a rapidly
expanding subject of computationally intensive algorithms that characterize
developmental capabilities and understanding by studying from its surrounds and
environment.. (Tsang,2005)
Using
annotated circuitry, the model may be tested for effectiveness and improve over
duration. When it comes to data gathering, there are two types of classifiers:
categorisation and extrapolation. A unsupervised algorithm correctly
categorises test data into certain groups in classification techniques.
Decision tree algorithm, linear classifications, support vector machine (svm)
and regression trees are examples of classification algorithms. The other one
is modelling, which analyses the relationship between the different variables
using an algorithm.
Machine learning is a discipline of
computer programming that tries to teach computers how to carry out tasks by
using machine learning and making machines personality. Computer software can
be divided into three sorts, what we referred to as the 3 kinds of constructing
notions. The three main types of learning algorithms are monitored, unlabeled,
and evolutionary computation (Ayodele , 2012).
Deep classification is one of the
most basic types of learning algorithm. This type of classification algorithm
is educated and trained using classification model. When used in the right
circumstances, this type of learning technique can be quite effective, albeit
the data must still be labelled correctly for it to work. The machine learning
model develops to integrate a mappings between it occurrences of input
attributes and their labels naturally in this scenario. We may be able to make
fresh recommendations on completely undiscovered data using algorithms which
have been trained that use such instances.
The supervised strategy produces
more exact and dependable discoveries. This can be due to the truth that the
supervised algorithm�s data frame is well-known and named. This plot empowers
us to accumulate information or produce a information yield based on past
encounter. So it is most reasonable. Utilizing ability, it assists us in optimizing
execution criteria. Labeled information is information that has as of now been
checked with the fitting yield.
v Upgrades are continuously
required.
v Overfitting supervised
strategies is straightforward for anybody.
Example
Problems with character
recognition are an excellent extension of previous learning. The goal of this
series of puzzles is to predict the class description in a specific text
section. In document classification, anticipating the viewpoint of a chunk of
text, such as with a tweeting or a press release, is a major challenge. This is
often used in the e-commerce industry to help businesses identify unpleasant
client feedback.
The capacity to analyses
unstructured input is a benefit of an unstructured learning algorithm. To put
it another way, no human work or input is required to make the dataset
machine-readable. This enables the application to handle larger datasets. In
supervised methods, the computation labels enable it to detect the specific
thing of each relation between two pieces of information. Training process, on
the other hand, does not employ labels to solve problems, resulting in the
formation of hidden architecture. The programme abstractly analyses complex
correlations between pieces of information, requiring no human labour or
inputs. (L�heureux,
2017)
Information labelling requires a
part of human work and costs. Unsupervised learning tackles the issue by
learning and categorising information without the utilize of names.
v This strategy illustrates the issue
by learning and grouping data without the need for labels.
v Labels may be presented that after
information has as of now been categorised, making the method less difficult.
It�s incredible for identifying designs in information that aren�t simple to
find utilizing conventional approaches.
Without any past information, the
show learns from crude information. It is additionally a long strategy, thus
times taken is more, which reduces it�s
efficiency. The algorithm�s learning stage, which analyses and calculates all
conceivable outcomes, might take a long time. For certain ventures requiring
live information, persistent information nourishing to the show may be
required, coming about in wrong and time-expending results. The more highlights
there are, the more complicated it gets to be. We are able to get correct
information sorting metadata, and the result as information for unsupervised is
named and obscure. So since input flag is obscure and not tagged in progress,
the discoveries are less exact.
Example
Assume that an unsupervised
classification system is given a dataset including pictures cats and dogs. The
computer has not been educated on the particular dataset and has no idea what
the dataset's properties are. The unsupervised classification individual's
purpose is for it to distinguish visual and optically features without any
external intervention. The majority of the work will be done using an autonomous
learning approach to divide the image collection into groups based on the
visual commonalities.
This method provide a number of
benefits, many of which are listed below:
�
Save data throughout the whole network
Essentially to how information is
saved on the network or maybe than in a database in customary computing. In the
event that a couple of bits of information disappear from one area, the network
as a entirety continues to work.
�
The capacity to function with less information:
The data output provided by the ANN
after training might be inadequate or incorrect. The significance of the
missing data influences the poor performance.
�
A high level of falt tolerance:
The output production of an
artificial neural network is unaffected by the degradation of one or more
cells. This improves the networks� ability to tolerate malfunctions